![]()
|
What is real advantage of VLIW CPUs? The performance of CPUs themselves can be increased two ways. First - increase clock speed. However, silicon technologies have certain limits. To increase clock speed CPU must be manufactured using smaller transistor's size. For this moment (Jan 2000) it is 0.18 mkm. The clock speed limit for 0.18 mkm technology is somewhat around 800 MHz. Although 2000 MHz is not so far away (year 2002 - 2003), overclocking CPU by factor of two does not mean 100% increase of performance, mostly because of slow memory bus (800 MHz RUMBUS RAM is not panacea - RUMBUS modules are 16-bit only, unlike 64-bit PC100/PC133 SDRAM DIMMs). So there is second and no less tricky way - increasing number of instructions that could be executed by CPU in single clock cycle. First of all, it requires additional functional units, what adds large number of transistors and surely do not help to gain top MHz. Many functional units do not guarantee large number of simultaneously executed instructions. Imagine sequence of 8 CPU instructions (A, B, C, D, E, F, G, H) and CPU capable to execute 4 instructions per single clock cycle (what most modern RISC CPUs theoretically can do). CPU cannot execute instruction B if it depends on result of A. But it can execute instruction C if it is not dependent of A and B. This is called out of order execution. Furthermore, often CPU cannot sequentially execute instructions because of branches (usually every 6 instructions), which override sequential instruction execution. Let's assume that depending on result of C either D either E shall be executed (simplest example - if x is greater than y, z = 1, otherwise z = 2). In this case CPU will try to guess result of C and will execute D or E. This is called branch prediction. So, ideally our virtual CPU will execute 8-instruction sequence in 2 clock cycles: 1 cycle - A+C+D+F, 2 cycle - B+G+H, E is not used at this time. In real life this most likely will not happen. Why?
All modern CPUs have very complicated units for 1) rearranging instructions at run time for most effective out of order execution and 2) branch prediction. So, how VLIW CPUs overcome those limitations? Pretty smart. First of all, VLIW compiler packs several RISC instructions, which can be executed in parallel, into one long instruction. Second, VLIW CPU eliminates branch prediction errors by means of executing all branch outcomes. After evaluating branch, it throws away needless results. VLIW CPU have more functional units and registers than CISC or RISC CPU but do not needs instruction reordering and branch prediction units. Third, VLIW CPU has feature as speculative loading. Compiler inserts speculative load check instructions to avoid idle CPU cycles while data loading from slow memory. In theory, VLIW CPUs have less transistor count and are better scalable rather RISC CPU. Let's draw an analogy with mechanical process. Imagine robots which take boxes from the conveyor and put them into containers. CISC robot have to deal with boxes of different shapes and sizes. In opposite, RISC robot is being supplied only with boxes of the same shape and size. CISC robot with RISC core has special device which split boxes apiece, which in turn, must be the same size and shape. VLIW robot receive small boxes already glued together to fit container. Now think, which robot will have top performance and less complex mechanic (taking into account that all containers have the same capacity)? Does RISC really fall behind? In future, may be, but not right now.
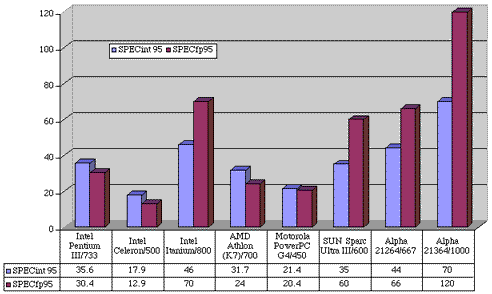
Below you can find SPEC performance numbers for some currently shipping (January 2001) and sampled CPUs (higher scores mean better performance). For sampled CPU (Itanium, SUN Sparc Ultra III, Alpha 21364) SPEC numbers are estimated.
How to get the most of current RISC? Are benchmark scores really represent real world performance? Let's review some optimization & benchmarking tricks. Continued... |