![]()
|
Optimization & Benchmarking Tricks Performance of software running on RISC CPU heavily depends on quality of codes generated by compiler. There are several pretty interesting methods of speeding up software.
Effect of those optimization techniques have been tested using BYTEmark benchmark suite. BYTEmark BYTEmark is single-threaded cross-platform test suite developed by BYTE Magazine. BYTEmark measures CPU core performance relative to Pentium 90, whose integer and floating-point index = 1, and estimate CPU performance running scientific and other calculation-intensive tasks (they do not reflect overall system performance, which is heavily depend on main board architecture, video card and disk subsystem). Full description of BYTEmarks can be found at BYTE web site. Here is brief description from BYTEmark FAQ.
How test were done. BYTEmark sources have been compiled using Apple MrC 4.1 under MPW (MrC stands as Macintosh RISC C, not Mister C) and Metrowerks CodeWarrior Pro 5.3 using different compiler settings. BYTEmark compiled with MrC later undergone dynamic optimization (+ block rearrangement) using Apple MrPlus. Tests run on iMac (333 MHz PowerPC G3/512 KB L2 Cache, MacOS 8.6) and Power Mac 7200 (75 MHz PowerPC 601, no L2 Cache, MacOS 8.6). Both Macs run in real-life mode (i.e. VM on, standard extensions loaded). Loading MacOS with extensions off resulted only few % improvement. Test 1 - Instruction Scheduling Benchmark (iMac 333, MacOS 8.6, CodeWarrior 5.3, global & local optimization off).
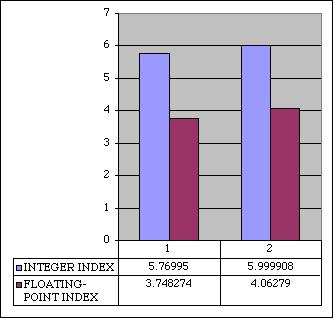
It seems Instruction Scheduling alone really will not give us very much (less than 4%). PowerPC out of order execution mechanism is indeed very good. Test 2 - Optimized and Non-optimized Code Performance Comparison (iMac 333, MacOS 8.6).
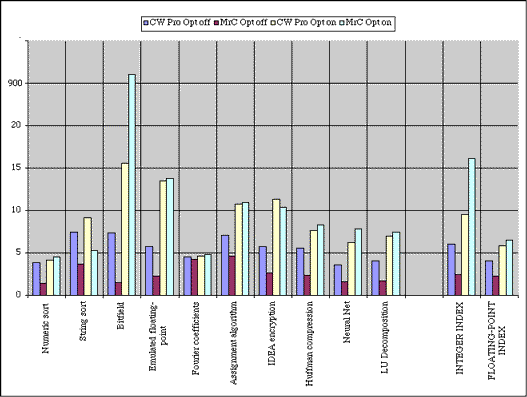
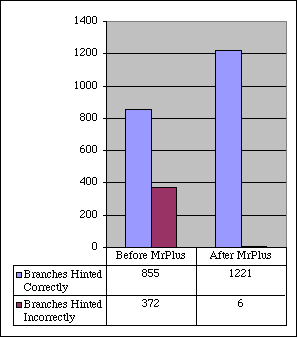
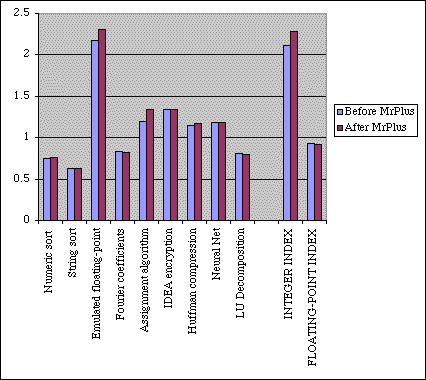
Please take a look at Bitfield test. BYTEmark compiled with MrC have enormous performance number shown in Bitfield test - above 900. This is not a bug, some earlier versions of CodeWarrior were able to generate approximately the same score. I do not know the reason of so vary results. If you look at another tests, you will see that performance of CodeWarrior and MrC compares. Due to high Bitfield result MrC topped BYTEmark Integer Index by significant degree. That's another lesson - unusually high score in one test can draw biassed judgment. Dynamic optimization based on profiling Apple Code Coverage & Performance Tool called MrPlus allows to generate enhanced version of executable with special codes which instrument branches, record and output statistics collected during run time. This data later used by MrPlus for updating branch prediction hints and block rearrangement (block rearrangement changes order of executable code, moves unused blocks to the end of code section and thus, improves the efficiency of the instruction cache). Test 3 - Branch Hint Report.
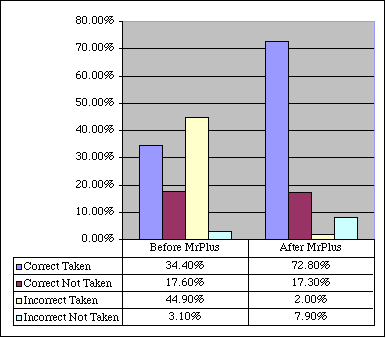
Profiling shows huge improvement of branch hint efficiency after dynamic optimization. How this reflect real-world performance? In BYTEmark case - few %. At a glance, looks sadly, isn't it? What is wrong? We must take into account nature of BYTEmark executables.
Unfortunately, I do not have any benchmark test with source codes which could be compiled into 2 MB or so executable to overflow L2 cache. If you can suggest such test I will be welcome. I tried perform bench test with cross-platform, open-source Crystal Space 3D Engine, which supports software-only 3D rendering (along with SGI OpenGL, 3dfx Glide, MS Direct 3D). Software-only 3D rendering would be ideal to test efficiency of optimization. Current version of Crystal Space is beta 015 (really 015, not 1.5) and is extremely unstable, it even does not run on some machines. Unfortunately, only one shared library (3D Software Renderer) could pass profiling and optimization. Attempt to profile bench test application itself and 2D graphic library finished with either freeze either crash. Probably we have to wait for more stable release of Crystal Space. I used old dusty Power Mac 7200/75 (without L2 cache at all) to verify assumption that BYTEmark suites have been loaded in L1 cache. Test 4 - BYTEmark scores on Power Mac 7200/75 without L2 cache.
Each cache miss could result up to 100 CPU idle cycles. After dynamic optimization BYTEmark integer index grew 8%, floating-point index somehow dropped 1% (1% is in range of standard variation). Only Bitfield test really show significant improvement (38%, not shown in the graph because score exceed 100, yet other scores are below 2.5). This test confirms assumption of L1 cache impact. By the way, 8% is not so few if we take into account that we optimized already highly optimized codes. The final words:
|